 Llama Cloud
免费
Llama Cloud
免费
Llama Cloud 面向 RAG 场景提供文档摄取、索引与检索服务,便于团队快速搭建企业知识问答系统。
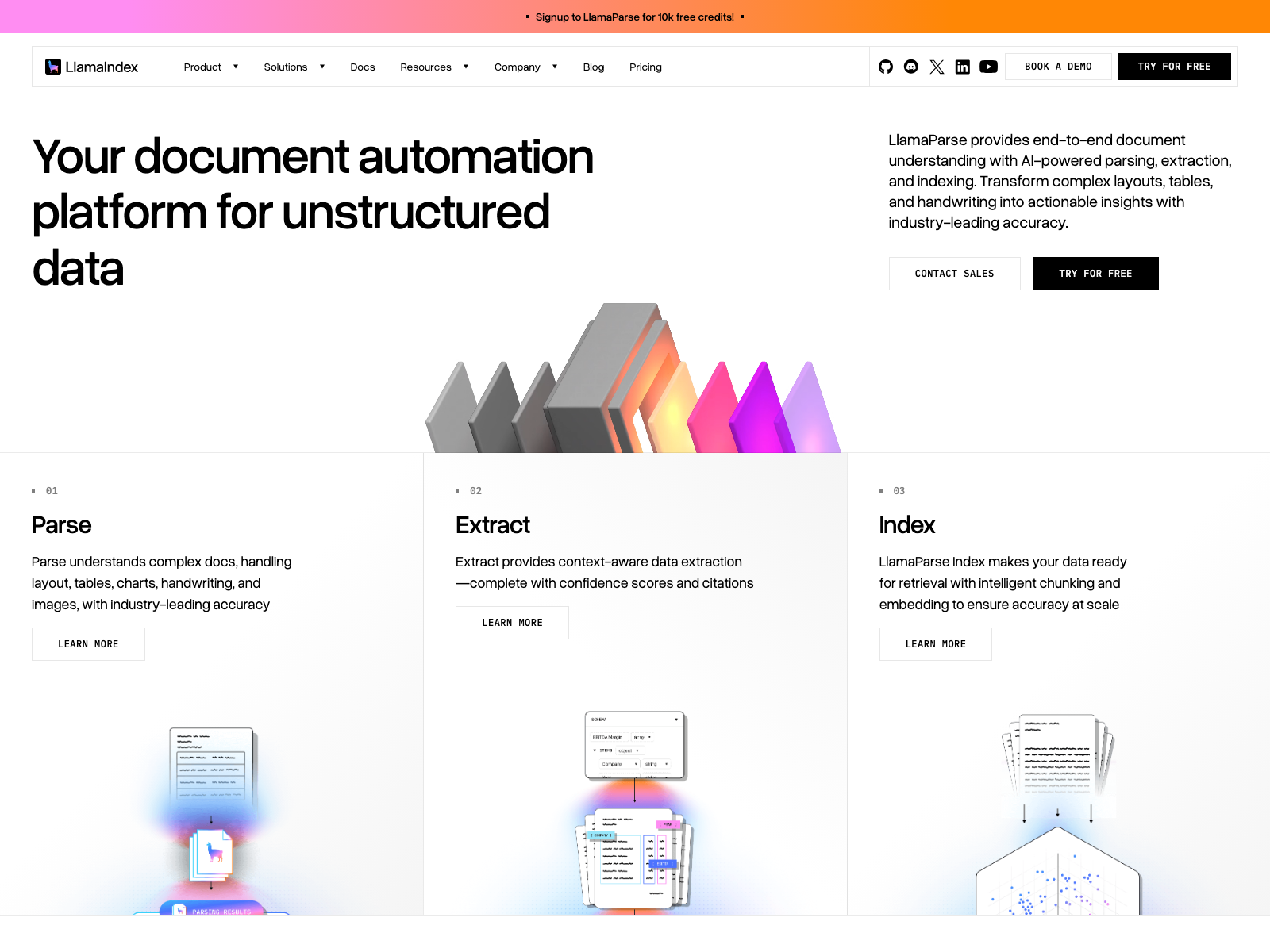
Llama Cloud
核心参数与统计
| 参数 | 说明 |
|---|---|
| 官方定位 | Document automation platform for unstructured data |
| 关键组件 | Parse / Extract / Index |
| 核心问题域 | 非结构化文档理解与可检索化 |
| 目标用户 | 文档密集型 RAG 团队 |
| 交付形态 | 托管服务(具体能力以官网实时页面为准) |
一句话简评:Llama Cloud 解决的不是“检索引擎缺失”,而是“文档数据脏乱导致 RAG 失真”。
宣传核验:其官方叙事强调复杂文档解析,真实竞争力应看字段抽取准确率和版式保真,而非单纯解析速度。
用户与市场认可
行业认可点:文档复杂度高的行业更容易感知它的价值,例如法务、金融、制造知识库。
市场认知位置:它并非“通用大模型平台”,而是 RAG 数据层中的文档理解基础设施。
核验提醒:企业级背书可作为参考,但采购时仍需用自有文档集做盲测,避免样例偏差。
成本优势
显性收益:
- 降低自建文档解析管道的人力成本。
- 减少因版式错误导致的人工校对成本。
- 缩短从“原始文档”到“可检索语料”的上线周期。
隐性成本:
- 增量同步频繁时,重解析费用会放大。
- 字段抽取规则一旦绑定业务逻辑,维护成本持续存在。
- 错抽/漏抽会转化为业务风险成本,而非纯技术问题。
合规与风险:文档可能包含敏感条款,必须核验数据驻留、加密、保留期限与删除策略。
主要功能
Parse:面向复杂 PDF/扫描件做结构化解析。
Extract:按字段语义抽取关键信息并保持上下文关系。
Index:将解析结果转为可检索索引,供问答和 Agent 调用。
连接器能力:对接常见文档来源,降低搬运成本。
隐藏联动(专家视点):
- Parse 质量直接决定 Extract 准确率,Extract 决定 Index 命中质量,三者是链式放大关系。
- 这意味着 RAG 效果问题常常根源在数据前处理,而不是模型本身。
模型与版本演进
Llama Cloud 的对外更新更偏组件能力增强,传统固定版本号披露有限。
建议按以下节奏追踪演进:
- 解析引擎升级(对复杂版式兼容度变化)。
- 字段抽取能力升级(抽取准确率变化)。
- 索引与检索策略升级(召回与时延变化)。
上线团队应保留每轮升级前后的基线对比报告。
技术优势
结构理解深度:在表格、层级、跨页信息上具备明显优势。
检索前置优化:通过前置清洗提高后续召回稳定性。
可运营性:适合长期维护的数据管道,而非一次性实验。
为什么有效:机制上先做文档理解再做检索,减少“语料本身错误”对生成结果的污染。
如何使用
- 选取高价值文档集(合同、制度、技术手册)建立 PoC。
- 优先验证 Parse + Extract 的字段准确率和漏抽率。
- 接入检索链路,对比改造前后问答命中率。
- 补齐增量同步、失败重试、人工复核后再生产放量。
推荐验收指标:字段准确率、召回率、错误答案率、人工纠错时长。
产品定价
| 套餐 | 官方披露 | 采购建议 |
|---|---|---|
| 试用 | 提供试用入口 | 优先测准确率而非仅测速度 |
| 团队 | 以官网实时页面为准 | 关注文档规模与并发配额 |
| 企业 | 商务沟通 | 核验合规、网络隔离、SLA |
单页解析单价不能代表总成本,重试率与人工复核成本必须计入。
应用场景
高收益场景:
- 法务与财务条款检索。
- 企业知识库高准确问答。
- 长文档字段抽取与流程自动化。
可扩展场景:
- 需要稳定文档上下文输入的 Agent 系统。
适用人群
强适配:文档复杂、对准确率有硬要求的企业团队。
强适配:已做 RAG 但效果被数据质量拖累的团队。
劝退人群:纯文本小规模语料、无需复杂解析的轻量项目。
总结与展望
Llama Cloud 的关键价值是把文档理解前置,减少后续 RAG 链路的系统性误差。
对文档密集业务,它通常能明显提高检索和问答稳定性;对轻量语料场景,存在能力过剩和投入回报不匹配风险。
后续评估重点应放在三项:解析准确率稳定性、增量同步成本、合规落地可执行性。
版本信息
- 首次公开发布 :早期版本信息未完整公开,建议以官方更新日志为准。
- Llama Cloud Q2 2026 :持续优化稳定性与开发者体验,具体能力以官方实时发布为准。
用户评价