DeepSeek融资500亿全解析:梁文锋自掏200亿,外部投资方无投票权
DeepSeek完成500亿首轮融资,梁文锋个人出资200亿成最大投资方,外部机构无投票权无董事会席位,五年锁定期。融资核心目的是期权定价和算力储备,而非填补资金缺口。
DeepSeek融资500亿全解析:梁文锋自掏200亿,外部投资方无投票权
6月16日,DeepSeek完成首轮外部融资,募资超500亿元,估值突破3380亿元,刷新国内AI单轮融资纪录。但比数字更耐人寻味的,是藏在数字背后的交易结构——创始人梁文锋个人出资200亿元,占本轮融资比例约四成,出资额超过任何一家外部机构:腾讯100亿、宁德时代50亿、京东和网易各约30亿、国家AI基金约10亿、IDG资本和砺思资本等也在名单上。
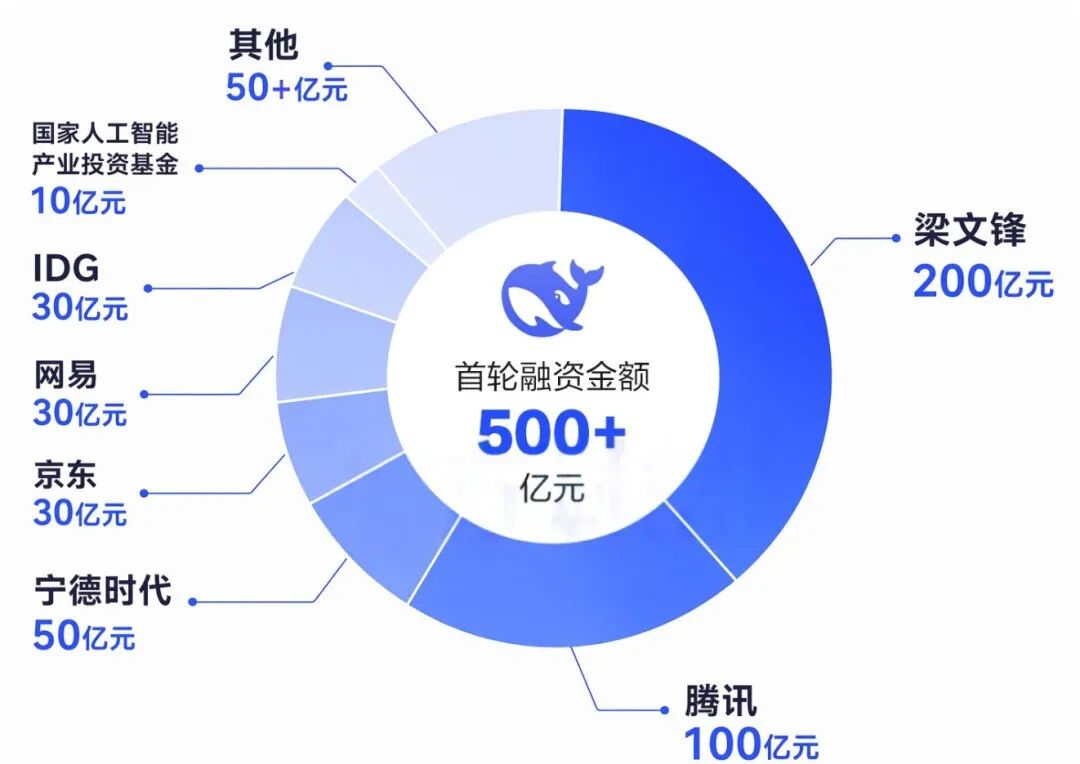
翻译成白话:钱进来了,方向盘谁也别想摸。一场融资,融出了"甲方变乙方"的魔幻戏码——理论上需要被投资的那个人,反而掏出了最多的钱,主客关系彻底颠倒。
三重控制权保险
梁文锋对控制权的保护,被结构性设计进了交易的每一层法律文本。
第一重:资金走"池子"不走公司。 除国家AI基金外,外部投资者被要求将资金注入由梁文锋管理的有限合伙企业,而非直接投资DeepSeek公司本体。外部投资者获得的是经济权益、优先参与未来融资的权利以及更高权限的财务信息——但投票权,没有。用大白话说:你投的钱不是直接买DeepSeek的股权,而是进了一个由梁文锋控制的"资金池"。
第二重:五年锁定期。 多数投资者在五年内不能出售所持权益,中途无法随意退出。在AI这个"三年上市、五年退休"的浮躁赛道里,五年锁定期等于把短期套利的念想直接掐断。DeepSeek团队还要求核查所有出资基金背后的有限合伙人真实身份,规避股权最终流入不明主体手中的风险。
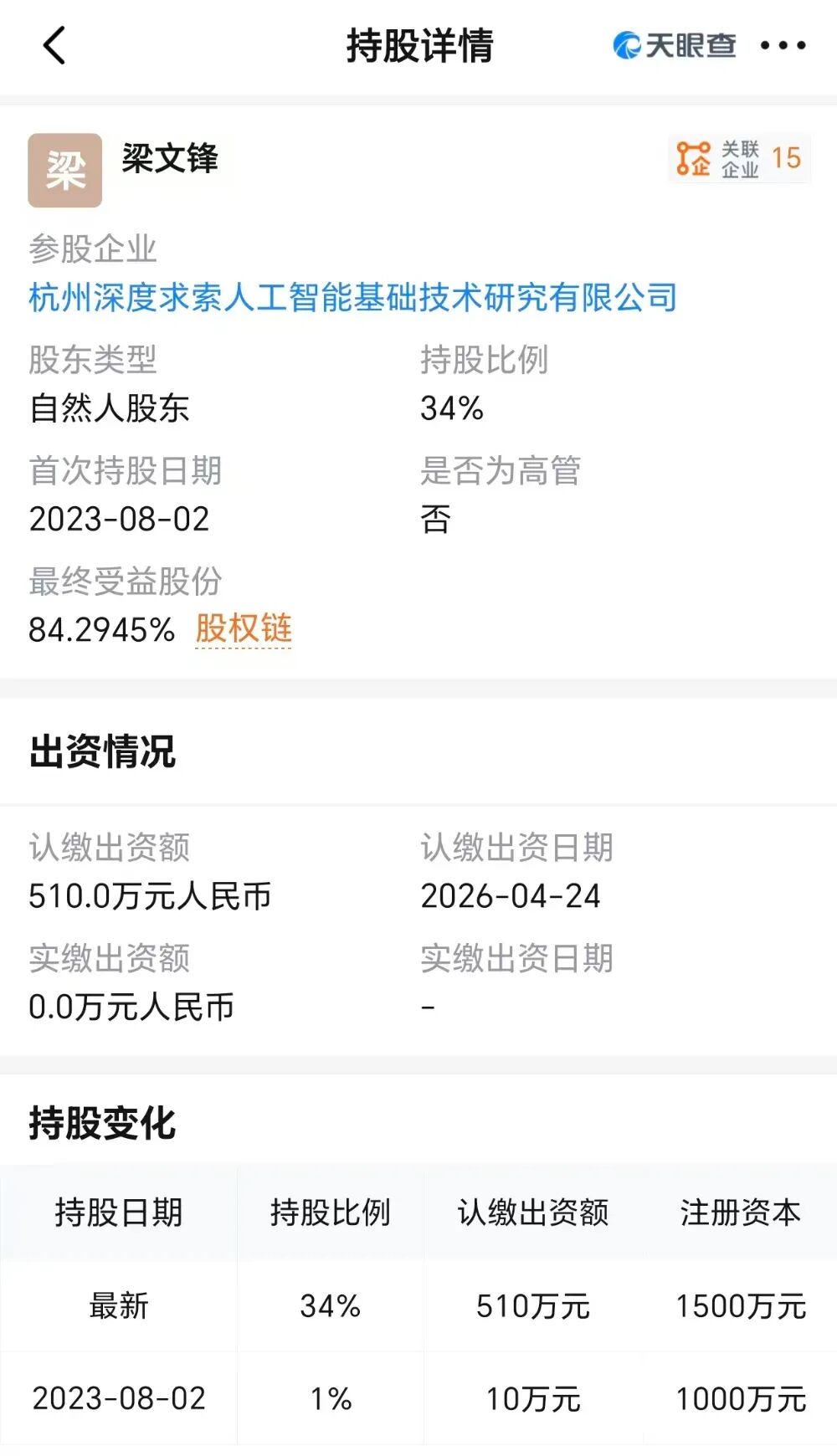
第三重:股权结构焊死。 融资前梁文锋先通过工商增资将个人直接持股比例从1%跳升至34%,叠加幻方系公司间接持股后,最终受益股份达84.29%,手握100%表决权。国家AI基金直投约10亿元是唯一例外,享有投票权且不受锁定期约束。连腾讯这样量级的机构,在这轮融资里也只能做纯粹的财务投资方——进了门,却上不了桌。
强势的底气:幻方量化的现金机器
梁文锋敢于设计如此"霸道"的交易结构,根基在于他另一重身份——国内头部量化私募幻方量化的创始人。幻方量化当前管理规模超700亿元,2025年收益均值56.55%,近三年均值85.15%,近五年达114.35%。不管二级市场如何震荡,每年都能持续产出可观的管理费与业绩分成。这是一台不依赖任何外部输血、可以自行造血的现金机器。

DeepSeek成立于2023年7月,最初只是幻方量化内部孵化的AI业务部门。成立前三年几乎未开放外部融资,全部研发投入由自有资金支撑。这在烧钱如流水的大模型赛道里极为罕见——行业多数玩家依赖VC输血,每轮融资都必须交出增长曲线和商业化故事,难免跟着融资节奏调整战略,长期技术积累空间被压缩。
也正因如此,本轮融资的核心诉求从一开始就不是填补资金缺口,而是解决两个更具体的问题:
其一,给员工期权做市场化定价。 过去一年,DeepSeek至少5名核心研发成员确认离职:V3核心贡献者罗福莉被雷军以千万年薪挖至小米,其MiMo团队推出的模型在部分基准测试中已超越DeepSeek同类产品;R1核心研究员郭达雅入职字节;第一代大语言模型核心作者王炳宣去了腾讯。非上市公司的期权没有流通市场,员工手里的激励说白了就是纸——与其说是融资,不如说是给人才一个"你的期权值多少钱"的市场化答案。
其二,为下一代模型训练储备算力弹药。 AI Agent时代的算力需求是另一个量级的游戏,仅凭幻方利润的滚动积累已不足以覆盖下一阶段的竞争烈度。

这是一轮带着明确战略目的的融资,而不是一次被迫出门找活路的救场之举。正是这层现金流底气,才让坚持开源、深耕长期AGI路线不再只是创始人的情怀表态,而是有制度支撑、有钱托底的真实选择。
路线突破:跳出硅谷坐标系
过去两年,国内AI行业始终绕不开一套对标硅谷的叙事框架——OpenAI融资国内就跟着融资潮,谷歌闭源国内就讨论开源生死,英伟达芯片稀缺国内就集体GPU焦虑。鲜有人停下来问一句:中国的AI发展,是不是一定得走那条路?
DeepSeek的这套组合拳——创始人绝对控股、自有现金流托底、绑定国产算力底座、坚持长期开源路线——在硅谷创业模板里找不到任何对应样本。它既不属于YC塑造的VC驱动模式,也区别于国内互联网大厂以流量生态绑定市场份额的经典打法。这是一条从自身商业基因里长出来的路径,不是从外部剧本里套进来的复刻版本。

一个值得单独拎出来的细节:国家AI基金直投约10亿元,保留投票权且不受锁定期约束——这是整套架构中唯一的例外。DeepSeek在商业逻辑上拒绝了所有机构的控制权,却在算力层面给国家队留了一扇始终开着的门。这不是矛盾,这是现实:算力作为AI时代的战略资源,注定要在国家战略和企业自主之间找到平衡点。
事实上,DeepSeek V4发布的同时,华为宣布昇腾超节点全系列产品已全面支持DeepSeek V4系列模型。昇腾950与昇腾A3超节点完成芯模技术协同适配,并提供基于昇腾A3的训练参考实现,支撑模型从训练到推理的全流程落地。多位业内人士表示,这标志着国产大模型和国产算力芯片已经打通了从训练到部署的全流程。

当然,这条路上的挑战同样不能回避——前沿模型训练成本持续攀升,开源所承担的商业代价逐年扩大,个人意志能否长期有效平衡产业规律。但有一点已经确定:DeepSeek为中国AI开辟了一条不再需要参照硅谷坐标系来丈量自身的独立路径。
500亿融资落地,是行业分化的里程碑。梁文锋走了一条硅谷写不出的路:创始人控股84%,自己掏出最大一笔钱,国家队跟投但仅限于算力层面,模型路线与国产芯片深度绑定。当资本的狂欢退潮,能笑到最后的未必是钱最多的那个,而是把整副牌攥在自己手里的人。
后续值得持续跟踪的几个方向:
- 期权激励实际效果:市场化定价能否真正止住核心研究员流失?5名已离职的案例是否会持续增加?
- 华为昇腾适配进展:V4在昇腾上的实际推理性能与NVIDIA的差距能否持续缩小?全栈适配后的商业化部署进度
- V4.1多模态商业化:计划推出的企业级多模态模型定价和交付方式
- "无投票权"股东的战略协同:腾讯、宁德时代等在缺乏话语权的情况下如何与DeepSeek实现产业协同
- 幻方与DeepSeek的长期解耦:量化业务利润波动是否影响对DeepSeek的持续输血?未来是否会进一步独立?
用户评价